Abstract
之前大部分工作都是对幽默的识别,即判断文本是否幽默。在该文中,作者做出了三点贡献:
- 作者提出了一个新的任务:判断一个笑话是否是幽默(强幽默和弱幽默)。
- 作者从Reddit收集了16000条幽默文本,并根据网页上的点赞数标注文本的幽默程度。
- 作者基于Transformer的结构,实现了对上述文本幽默等级的预测。
作者证实了模型的性能与人类基准是可比的。
作者还进一步验证了模型在原先的幽默识别任务上也带来了提升,他使用了已有的短幽默语料和双关语语料。
Introduction
作者列了幽默在分类、生成和社交媒体等方面的工作,可以关注一下。
然后作者对Reddit一阵猛吹。Reddit论坛笑话多,用户多,其他语言的幽默论坛都没有它这么赞。Reddit笑话不仅有正文,还抽取出了笑点,每个笑话还有点赞数。
尽管Reddit上的笑话受众有限,但数量也较充足。作者认为研究Reddit的幽默文本,是研究大量人群对幽默反应的一个有效方法。
Related Work
作者简单描述了相关的幽默工作,基本都看过了。
Data
作者使用了三个幽默数据集。
作者使用Reddit的公共API爬取了最新的幽默文本,每次爬取数据的时候,爬虫也会更新幽默文本的点赞数。数据的爬取工作每小时进行一次,整个工作持续了两个月。观察数据集发现,实际只有15910条数据。
作者发现大部分笑话的点赞数在0200之间,只有6%的笑话点赞数在20020000之间。作者采用了一个“自然划分”的方法,获得了13884条不是很有趣的笑话和2025条无趣的笑话。但是作者这个“自然划分”的描述也太模糊了吧,难道是我没看懂吗?
作者构建的数据集包括笑话的正文、笑点、点赞数,例子如下:

Short Jokes
该数据集的231657条正例从Kaggle获取,负例由作者自己爬取新闻标题构建。
Pun of the Day
该数据集是作者联系Yang获取的,有16001条双关幽默正例和16002条新闻标题负例。
作者这里描述错了,正例2423条,负例2403条。
Methods
Our Model
作者没有Model,作者就是用了BERT。
Training
由于构建的Reddit数据集是不平衡的,作者决定进行采样。
- 作者先按照3:1的标签比例将数据集划分为训练集和验证集。
- 作者对训练集中的少数类别进行上采样,直到类别均衡(各占50%)。
- 作者又对验证集做负采样直到类别均衡(各占50%)。
作者在三个数据集上比较了BERT和之前的一些经典模型(惊了)。
Experiments
作者分别在三个数据集上进行了实验。
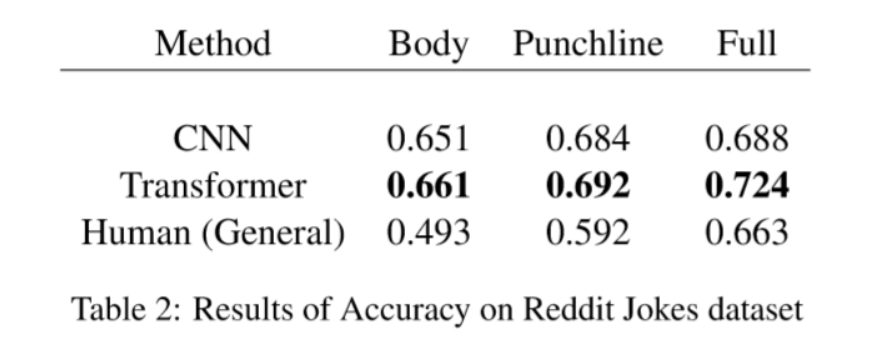
- CNN:结合了High Way的CNN。
- Transformer:就是BERT。
- Human:作者邀请199个人进行了标注,平均每个人标注约30条样本(30条认真的?不是80条吗?)。每条样本由三部分组成:除去笑点的Body,笑点Punchline,Body+Punchline=Full。作者先让受试者单独标注Body和Punchline是否好笑,然后再问受试者基于Punchline的Full是否好笑。
结果没什么好说的,BERT牛逼。作者又探究了Body和Punchline哪个在幽默中更重要,三个实验结果都表明,还是Punchline重要一些。作者解释说这是由于不同笑话Body之间较大的差异造成的,有的Body很长,有的不足一句话。这个解释很牵强。
Short Jokes

BERT牛逼就完了。
Pun of the Day
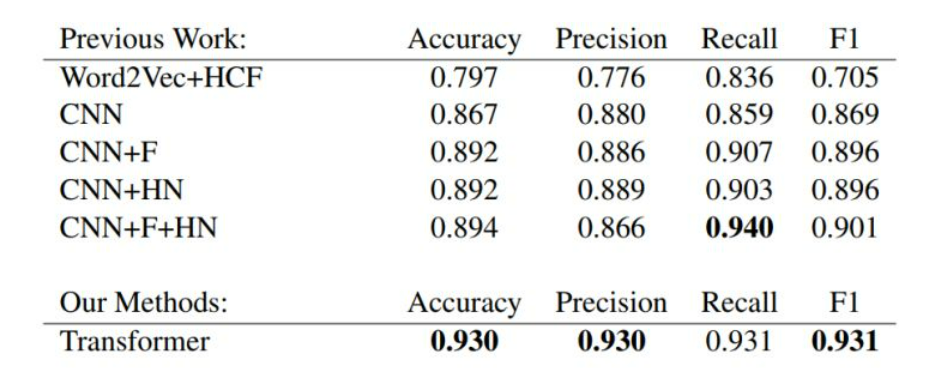
BERT连战连捷。
Discussion
- 一般人群与Reddit用户的偏好之间存在明显差异(第一个实验)。 作者认为BERT可以学习Reddit用户所认可的特定幽默类型。这表明可以为特定的人群子集学习幽默。
- 模型在实验二、三上表现良好,表明模型可以进行很好地迁移。模型得到这么好的结果是在预期之内的,因为如果模型可以预测哪个笑话更有趣的话,用它判断文本是不是笑话也是没有问题的。
Conclusion
这篇论文还是很水的。想讲个笑话,ICML改变世界,EMNLP改变我的三观。
总结一下学到的东西吧。作者的立意,有两点还是不错的。
第一,将笑点和笑话的其他文本区分开,关注笑点在幽默中的作用。
第二,作者将特定受众与一般人群区分开,得出结论,认为基于Transformer的BERT可以预测文本对于特定受众的幽默程度。